.png)
Operationalisierung von Zero Trust – Schritt 5: Entwerfen der Richtlinie
Diese Blog-Serie erweitert die Ideen, die ich in meinem März-Beitrag "Zero Trust ist nicht schwer ... Wenn man pragmatisch ist."
In diesem Beitrag habe ich sechs Schritte zum Erreichen von Zero Trust skizziert, und hier möchte ich auf einen dieser Schritte eingehen, nämlich das Entwerfen der Richtlinie. Ich zeige Ihnen, wie dieser Schritt die Implementierung eines soliden Frameworks unterstützen kann, das von jedem Mikrosegmentierungspraktiker verwendet werden kann, um seine Projekte erfolgreicher zu machen, unabhängig von der Größe der Organisation.
Bevor ich beginne, hier eine Auffrischung der sechs Schritte:
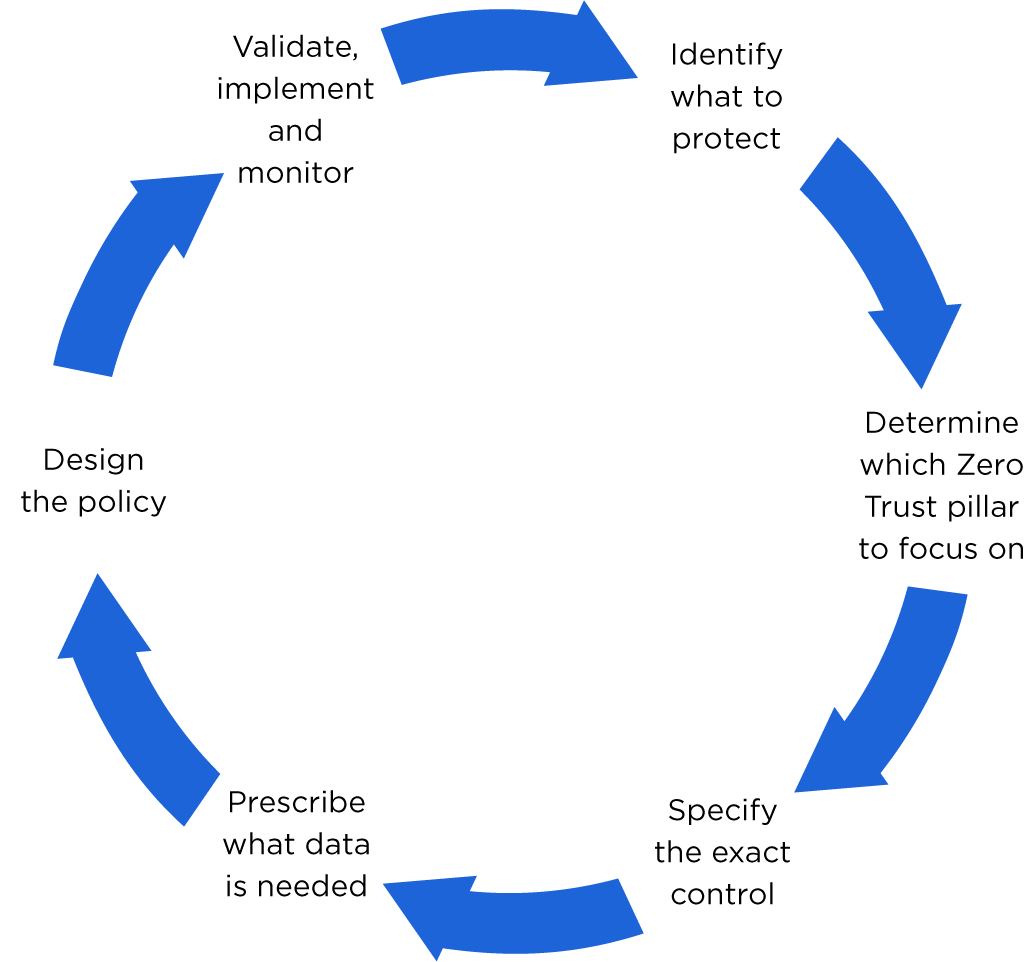
Schritt 5: Entwerfen der Richtlinie
Im letzten Beitrag dieser Serie habe ich mich mit dem Thema "Vorschreiben, welche Daten benötigt werden" befasst. In diesem Artikel habe ich den folgenden Punkt angesprochen:
"Einer der wichtigsten Aspekte von Zero Trust – und es wird nicht annähernd so viel Berichterstattung erhalten, wie es sollte – ist, dass eine effektive Implementierung von Zero Trust auf den Zugriff auf Kontextinformationen oder Metadaten angewiesen ist, um Richtlinien zu formulieren. Wenn es also um Mikrosegmentierung im Zusammenhang mit dem Schutz von Workloads geht, beschreiben die minimalen Metadaten außerhalb eines Standard-Traffic-Berichts die Workloads im Kontext Ihrer Rechenzentrumsanwendungen und -umgebungen."
Basierend auf dieser Aussage sind die drei wichtigsten Daten, die wir benötigen:
- Echtzeit-Verkehrsereignisse für die Workloads, die wir schützen möchten.
- Kontextdaten für jede Workload und Verbindung: Dazu gehören Metadaten, die mit der Workload verknüpft sind und aus einem Aufzeichnungssystem wie einer CMDB stammen würden, sowie Informationen wie Details zum Kommunikationsprozess, die direkt aus der Workload stammen. '
- An Anwendungsabhängigkeitskarte (abgeleitet von den Elementen 1 und 2), die es einem Anwendungseigentümer oder Segmentierungspraktiker ermöglicht, die vor- und nachgelagerten Abhängigkeiten einer bestimmten Anwendung schnell zu visualisieren.
Alles zusammenfügen
Jetzt sind Sie also fast bereit, diese Richtlinie zu erstellen, aber lassen Sie mich Sie an die Ziele erinnern:
- Sie möchten eine Mikrosegmentierungsrichtlinie erstellen, um Ihre Workloads zu schützen.
- Sie möchten, dass diese Richtlinie den Prinzipien von Zero Trust folgt.
- Daher dürfen die von Ihnen erstellten Regeln nur den Zugriff auf und aus den Workloads zulassen, die zum Ausführen ihrer Geschäftsfunktion erforderlich sind.
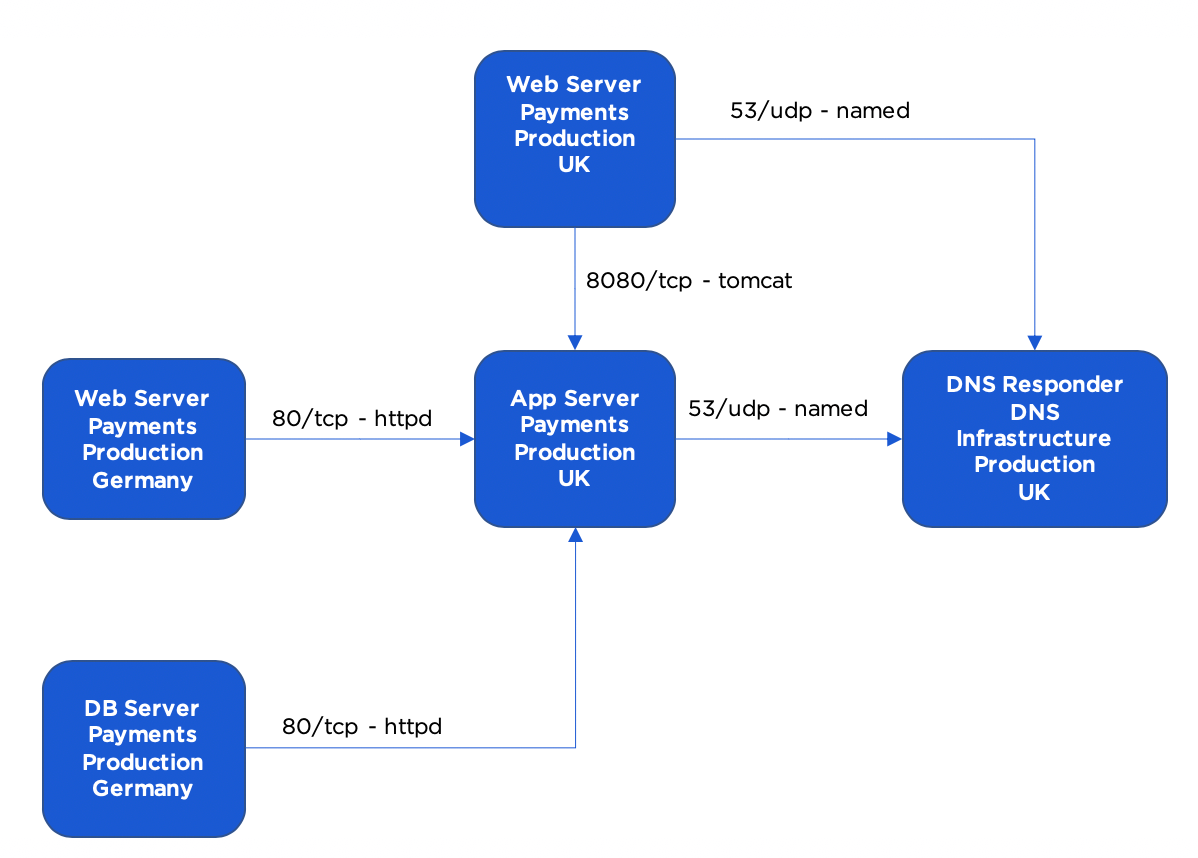
Im Anschluss an die Daten, die ich als "notwendig" bezeichnet habe, sehen Sie im Folgenden Beispiele für einige Datenverkehrsprotokolleinträge, die zum Erstellen einer Richtlinie verwendet werden können:
Verkehrsprotokoll-Verbindung 1:
- Quelle: 10.0.0.1, 10.0.0.2
- Quellkontext: Webserver, Zahlungsanwendung, Produktion, Großbritannien
- Ziel: 192.168.0.1
- Ziel: Kontext: DNS-Responder, DNS-Infrastruktur, Produktion, Großbritannien o Zielprozess: benannt
- Anschluss: 53
- Protokoll: UDP
- Aktion: Zulassen
Verkehrsprotokoll-Verbindung 2:
- Quelle: 10.0.0.1,10.0.0.2
- Quellkontext: Webserver, Zahlungsanwendung, Produktion, Großbritannien
- Ziel: 10.0.1.5,10.0.1.6,10.0.1.7
- Zielkontext: App-Server, Zahlungsanwendung, Produktion, Großbritannien
- Zielprozess: Tomcat
- Anschluss: 8080
- Protocol: TCP
- Aktion: Zulassen
Verkehrsprotokoll-Verbindung 3:
- Quelle: 10.0.1.5, 10.0.1.6,10.0.1.7
- Quellkontext: App-Server, Zahlungsanwendung, Produktion, Großbritannien
- Ziel: 192.168.0.1
- Ziel: Kontext: DNS-Responder, DNS-Infrastruktur, Produktion, Großbritannien
- Zielprozess: benannt
- Anschluss: 53
- Protokoll: UDP
- Aktion: Zulassen
Verkehrsprotokoll-Verbindung 4:
- Quelle: 10.1.0.1,10.1.0.2
- Quellkontext: Webserver, Zahlungsanwendung, Produktion, Deutschland
- Ziel: 10.0.1.5,10.0.1.6,10.0.1.7
- Zielkontext: App-Server, Zahlungsanwendung, Produktion, Großbritannien
- Ziel-Prozess: httpd
- Anschluss: 80
- Protocol: TCP
- Aktion: Zulassen
Verkehrsprotokoll-Verbindung 5:
- Quelle: 10.1.2.1,10.1.2.2
- Quellkontext: Datenbankserver, Zahlungsanwendung, Produktion, Deutschland
- Ziel: 10.0.1.5,10.0.1.6,10.0.1.7
- Zielkontext: App-Server, Zahlungsanwendung, Produktion, Großbritannien
- Ziel-Prozess: httpd
- Anschluss: 80
- Protocol: TCP
- Aktion: Zulassen
Auf diese Weise können Sie die Anwendungsabhängigkeitszuordnung schnell ableiten.
So weit so gut.
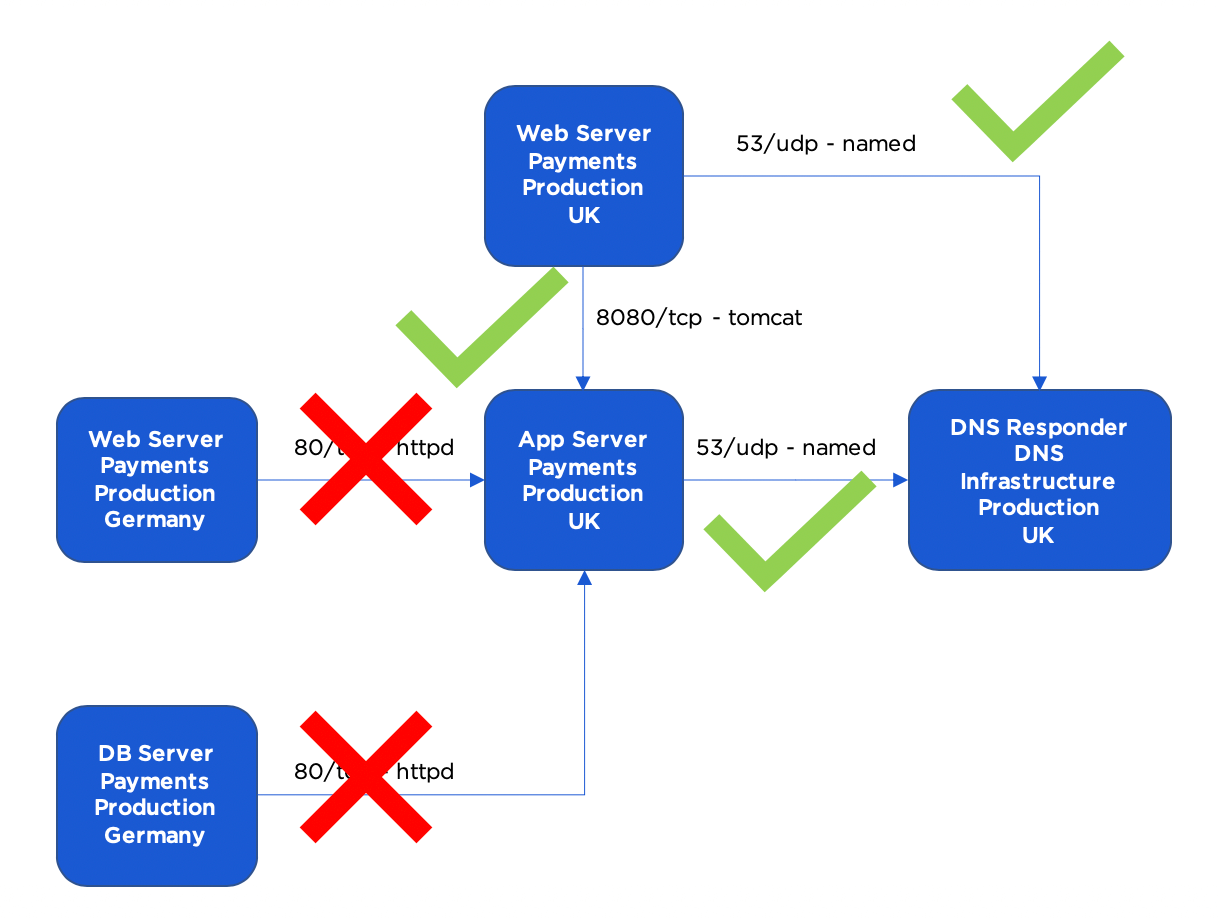
Jetzt können Sie sich Ihre Anwendungsabhängigkeitszuordnung ansehen, um zu bestimmen, welche Flows Sie tatsächlich zulassen möchten. Basierend auf der Kenntnis Ihrer Anwendung wissen Sie, dass die folgenden Abläufe erforderlich sind, z. B.:
- Webserver, Zahlungen, Produktion, Großbritannien -> DNS-Responder, DNS-Infrastruktur, Produktion, Großbritannien auf 53/udp
- App Server, Zahlungen, Produktion, Großbritannien -> DNS Responder, DNS-Infrastruktur, Produktion, UK auf 53/udp
- Webserver, Zahlungen, Produktion, Großbritannien -> App Server, Zahlungen, Produktion, Großbritannien auf 8080/tcp
Sie wissen auch, dass die folgenden beiden Flows nicht richtig aussehen und daher nicht in Ihre anfänglichen Regeln aufgenommen werden sollten:
- Webserver, Zahlungen, Produktion, Deutschland -> App Server, Zahlungen, Produktion, UK auf 80/tcp
- DB Server, Zahlungen, Produktion, Deutschland -> App Server, Zahlungen, Produktion, UK auf 80/tcp
Die Anwendungsabhängigkeitszuordnung, die Sie zum Erstellen von Regeln verwenden, sieht am Ende wie folgt aus:
Nun, wie drückt man diese Regeln eigentlich aus? Mit herkömmlichen Firewalls wären Sie gezwungen, diese anhand von Quell- und Ziel-IP-Adressen zu definieren. Auf diese Weise werden jedoch alle umfangreichen Kontextinformationen, von denen Sie beim Ermitteln dieser Flows profitiert haben, vollständig entfernt, und schlimmer noch, dass dieser Kontext erneut eingefügt werden muss, wenn die Regel überprüft wird. Was passiert auch, wenn Sie einen zusätzlichen DNS-Responder oder einen neuen App-Server oder Webserver für die Zahlungs-App hinzufügen?
Denken wir daran, dass Sie versuchen, eine Richtlinie zu entwickeln, die sich an die Zero-Trust-Prinzipien hält, nämlich sicherzustellen, dass es sich immer um die geringsten Privilegien handelt. Ein kontextbasierter Ansatz, bei dem eine adaptive Sicherheits-Engine im Hintergrund ihre Wirkung entfaltet, ermöglicht genau dies. So wie Ihre Richtlinie erweitert wird, um einen neuen Server mit vorhandenem Kontext zu integrieren, möchten Sie auch, dass Ihre Richtlinie verkleinert wird, wenn Sie einen Server außer Betrieb nehmen. Wenn Sie beispielsweise einen Ihrer DNS-Responder außer Betrieb nehmen, möchten Sie, dass alle Regeln, die zuvor den Zugriff auf / von ihm erlaubt haben, aktualisiert werden, sodass dieser Zugriff nicht mehr möglich ist. Das ist genau das, was die Policy Compute Engine (PCE) von Illumio tun soll: Die Mikrosegmentierungsrichtlinie wird anhand von Metadaten definiert, und die PCE bestimmt dann, welche Workloads zu diesem bestimmten Zeitpunkt mit den Metadaten übereinstimmen, um dann die tatsächlichen Regeln zu berechnen, die bei jedem Workload durchgesetzt werden müssen, um ihre Zero-Trust-Sicherheitslage aufrechtzuerhalten. Jedes Mal, wenn sich der Kontext ändert, passt der PCE die Richtlinie an und benachrichtigt die Workloads über Aktualisierungen.
Vor diesem Hintergrund läuft Ihre Zero-Trust-Richtlinie auf die folgenden Regeln hinaus:
Regel 1:
- Quelle: Webserver, Zahlungen, Produktion, Großbritannien
- Ziel: DNS-Responder, DNS-Infrastruktur, Produktion, Großbritannien
- Zieldienst: 53/udp
- Zielprozess: benannt
Regel 2:
- Quelle: App Server, Payments, Production, UK
- Ziel: DNS-Responder, DNS-Infrastruktur, Produktion, Großbritannien
- Zieldienst: 53/udp
- Zielprozess: benannt
Regel 3:
- Quelle: Webserver, Zahlungen, Produktion, Großbritannien
- Ziel: App Server, Zahlungen, Produktion, Großbritannien
- Zieldienst: 8080/tcp
- Zielprozess: Tomcat
Und das ist es.
Sind Sie bereit, den nächsten Schritt auf Ihrem Weg zu Zero Trust zu gehen? Besuchen Sie unsere Seite , auf der Sie erfahren, wie Sie Ihre Zero-Trust-Strategie mit Mikrosegmentierung operationalisieren können, um einen Einblick zu erhalten.


