.png)
Containers Anatomy 101: Was ist ein Cluster?
Aus der Netzwerkperspektive erweitern Container den Netzwerk-"Edge" – die Grenze zwischen Netzwerkweiterleitungsentscheidungen und dem Erreichen seines endgültigen Ziels durch ein Paket – tief in einen Host. Die Edge ist nicht mehr die Netzwerkschnittstelle eines Hosts, sondern steckt mehrere Schichten tief in logischen Konstrukten innerhalb eines Hosts. Und die Netzwerktopologie ist abstrahiert und reicht tief in diese logischen Konstrukte innerhalb eines Hosts hinein, in Form von Overlay-Netzwerktunneling, virtuellen Schnittstellen, NAT-Grenzen, Load Balancern und Netzwerk-Plugins. Netzwerk- und Sicherheitsarchitekten können bei der Gestaltung ihrer Architekturen die Interna des Betriebssystems nicht mehr ignorieren. Container zwingen diese Architekturen zu verstehen, wohin ein Paket geht, nachdem es die Netzwerkkarte eines Hosts durchlaufen hat.
Orchestrierungssysteme
Vor diesem Hintergrund ist ein Orchestrierungssystem erforderlich, um eine gewisse Ordnung in Containerumgebungen zu bringen. Ein Orchestrierungssystem verwaltet die Details rund um das Organisieren, Skalieren und Automatisieren von Containern und erstellt logische Konstrukte um verschiedene Komponenten, die für das Verhalten von Containern relevant sind. Sie sind auch für die Organisation logischer Grenzen verantwortlich, die Containerlaufzeiten zugeordnet sind, und für die Erstellung logischer Konstrukte, denen eine IP-Adresse zugewiesen werden kann. Allerdings sind solche Systeme extern und können den Lebenszyklus bestimmter Container-Runtime-Instanzen, die beispielsweise noch von Docker verwaltet werden, nicht bereitstellen und verwalten.
Es gibt viele Orchestrierungssysteme für Container, aber die beiden heute am häufigsten verwendeten sind Kubernetes und OpenShift. Beide erreichen die gleichen grundlegenden Ziele, mit dem Hauptunterschied, dass das eine ein Projekt und das andere ein Produkt ist: Kubernetes ist ein Projekt, das größtenteils aus Google hervorgegangen ist, und OpenShift ist ein Produkt von Red Hat. Im Allgemeinen ist Kubernetes am häufigsten in Public-Cloud-Umgebungen und OpenShift am häufigsten in lokalen Rechenzentren zu sehen, aber es gibt eine erhebliche Überschneidung zwischen den beiden. Kurz gesagt, Kubernetes liegt beiden Ansätzen zugrunde, mit einigen geringfügigen Unterschieden in der Terminologie zwischen den beiden.
Eine kurze Geschichte der Container
Ob Sie es glauben oder nicht, Container sind älter als Kubernetes. Docker zum Beispiel veröffentlichte seine Container-Plattform erstmals im Jahr 2013, während Kubernetes sein auf die Public Cloud fokussiertes Projekt erst 2014 veröffentlichte. OpenShift wurde vor beiden eingeführt, mit einem Schwerpunkt auf Hosts, die in lokalen Rechenzentren bereitgestellt werden.
Das einfache Bereitstellen von Containerlaufzeiten auf einem lokalen Host entspricht in der Regel den Anforderungen der Entwickler, da Laufzeiten über "localhost" und eindeutige Ports miteinander kommunizieren können. Containerruntimes werden keine bestimmten IP-Adressen zugewiesen. Wenn Sie sich darauf konzentrieren, schnellen und effizienten Code zu schreiben und Ihre Anwendung über eine Sammlung zugeordneter Containerlaufzeiten bereitzustellen, funktioniert dieser Ansatz gut. Wenn Sie jedoch möchten, dass diese Anwendung auf externe Ressourcen außerhalb des lokalen Hosts zugreift, oder wenn Sie möchten, dass externe Clients auf diese Anwendung zugreifen, können Sie Netzwerkdetails nicht ignorieren. Dies ist einer der Gründe, warum ein Orchestrierungssystem benötigt wird.
Kubernetes wurde um eine Reihe von Bausteinen und einen API-gesteuerten Workflow herum erstellt, um das Verhalten von Container-Laufzeiten zu organisieren. Bei diesem Ansatz erstellt Kubernetes eine Reihe logischer Konstrukte innerhalb und zwischen Hosts, die einer bestimmten containerisierten Umgebung zugeordnet sind, und erstellt ein völlig neues Vokabular, auf das auf diese Konstrukte verwiesen wird. Während Kubernetes diese Bausteine und API-gesteuerten Workflows auf eine Reihe von Rechenmetriken anwendet, die mit der CPU-Zuweisung, den Arbeitsspeicheranforderungen und anderen Metriken wie Speicher, Authentifizierung und Messung verbunden sind, konzentrieren sich die meisten Sicherheits- und Netzwerkexperten auf eine Sache:
Welche Grenzen durchläuft ein IP-Paket, wenn es sich auf dem Weg zu einem logischen Konstrukt befindet, dem eine IP-Adresse zugewiesen ist?
Aus der Netzwerkperspektive erstellen sowohl Kubernetes als auch OpenShift logische, relevante Konstrukte in einem hierarchischen Ansatz, mit nur einem geringen Unterschied im Vokabular zwischen den einzelnen Systemen. Dies ist im Folgenden dargestellt.
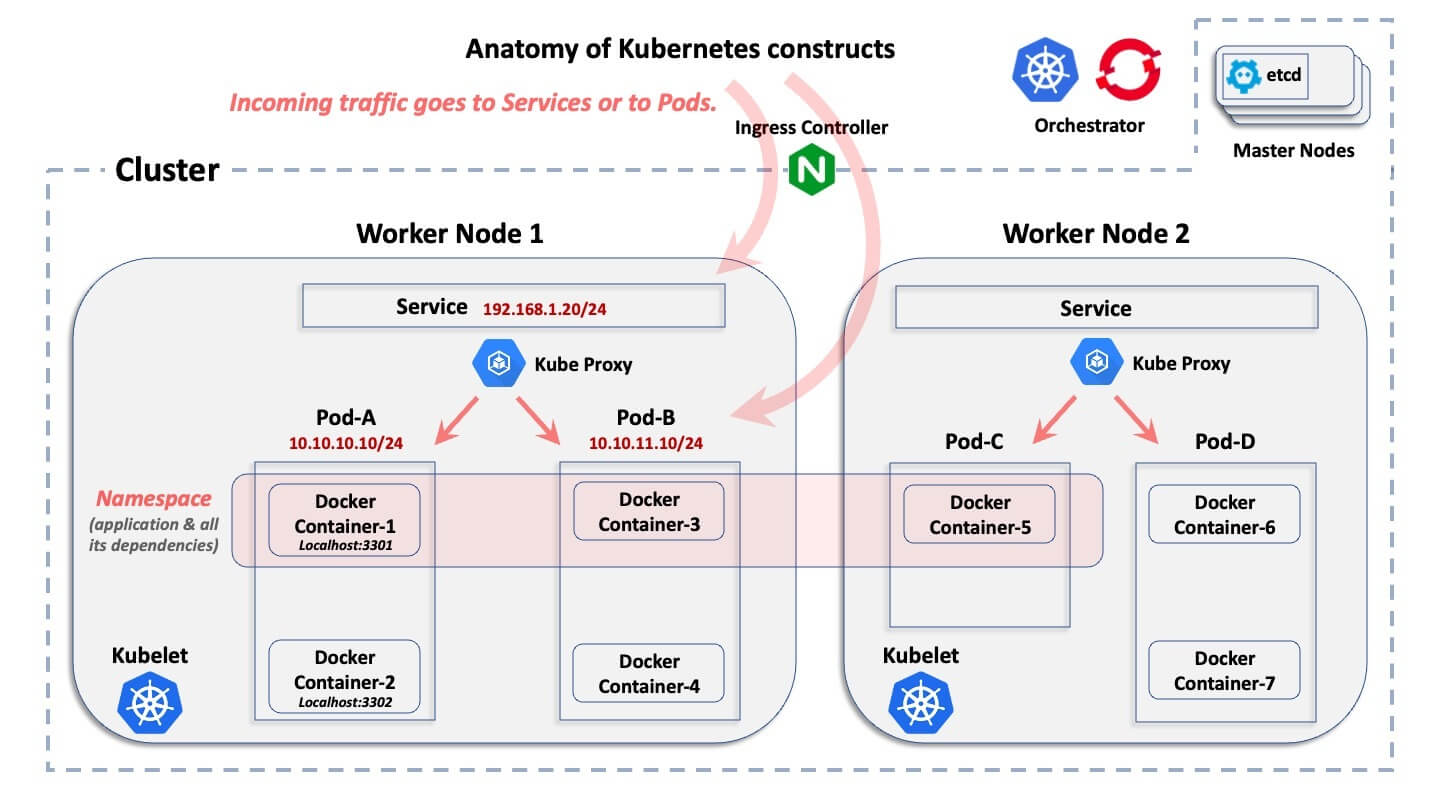
Das ABC eines Container-Clusters
Dieses Diagramm zeigt das grundlegende logische Konstrukt einer Kubernetes-Umgebung. Es wird nicht erklärt, was die einzelnen Konstrukte tun, sondern nur, wie sie logisch zueinander in Beziehung stehen.
Beginnend mit dem breitesten Konstrukt bis hin zum kleinsten, hier sind kurze Erklärungen:
- Cluster: Ein Cluster ist die Sammlung von Hosts, die einer bestimmten containerisierten Bereitstellung zugeordnet sind.
- Knoten: Innerhalb eines Clusters gibt es Knoten. Ein Knoten ist der Host, auf dem sich Container befinden. Ein Host kann entweder ein physischer Computer oder eine VM sein, und er kann sich entweder in einem lokalen Rechenzentrum oder in einer öffentlichen Cloud befinden. Im Allgemeinen gibt es zwei Kategorien von Knoten in einem Cluster: die "Master-Knoten" und die "Worker-Knoten". Um die Dinge zu vereinfachen, ist ein Master-Knoten die Steuerungsebene, die die zentrale Datenbank des Clusters und des API-Servers bereitstellt. Bei den Worker-Knoten handelt es sich um die Maschinen, auf denen die eigentlichen Anwendungs-Pods ausgeführt werden.
- Pods: Innerhalb jedes Knotens erstellen sowohl Kubernetes als auch OpenShift Pods. Jeder Pod umfasst entweder eine oder mehrere Containerlaufzeiten und wird vom Orchestrierungssystem verwaltet. Pods werden von Kubernetes und OpenShift mit IP-Adressen versehen.
- Container: Innerhalb von Pods befinden sich die Containerlaufzeiten. Container innerhalb eines bestimmten Pods haben alle dieselbe IP-Adresse wie dieser Pod und kommunizieren über Localhost über eindeutige Ports miteinander.
- Namespace: Eine bestimmte Anwendung wird "horizontal" über mehrere Knoten in einem Cluster bereitgestellt und definiert eine logische Grenze zum Zuweisen von Ressourcen und Berechtigungen. Pods (und damit Container) und Services, aber auch Rollen, Secrets und viele andere logische Konstrukte gehören zu einem Namensraum. OpenShift nennt dies ein Projekt, aber es ist das gleiche Konzept. Im Allgemeinen wird ein Namespace einer bestimmten Anwendung zugeordnet, die in allen zugehörigen Containern bereitgestellt wird. Ein Namensraum hat nichts mit einem Netzwerk- und Sicherheitskonstrukt zu tun (anders als ein Linux-IP-Namensraum)
- Dienst: Da Pods kurzlebig sein können – sie können plötzlich verschwinden und später dynamisch erneut bereitgestellt werden – ist ein Dienst ein "Front-End", das vor einer Reihe zugeordneter Pods bereitgestellt wird und wie ein Lastenausgleich mit einem VIP funktioniert, der nicht verschwindet, wenn ein Pod verschwindet. Ein Dienst ist ein nicht-kurzlebiges logisches Konstrukt mit einer eigenen IP-Adresse. Mit nur wenigen Ausnahmen innerhalb von Kubernetes und OpenShift verweisen externe Verbindungen auf die IP-Adresse eines Dienstes und werden dann an "Backend"-Pods weitergeleitet.
- Kubernetes API Server: Hier ist der API-Workflow zentralisiert, wobei Kubernetes die Erstellung und den Lebenszyklus all dieser logischen Konstrukte verwaltet.
Sicherheitsherausforderungen bei Containern
Um Sicherheitssegmente entlang von Workload-Grenzen zu erstellen, ist es notwendig, diese grundlegenden logischen Konstrukte zu verstehen, die von Kubernetes erstellt werden. Externer Netzwerkverkehr, der von der gehosteten Anwendung ein- und ausgegangen wird, verweist in der Regel nicht auf die IP-Adresse des zugrunde liegenden Hosts, des Knotens. Stattdessen verweist der Netzwerkdatenverkehr entweder auf einen Dienst oder einen Pod innerhalb dieses Hosts. Daher müssen die zugehörigen Dienste und Pods einer Workload ausreichend verstanden werden, um eine effektive Segmentierungssicherheitsarchitektur zu erstellen.
Interessiert an mehr? Lesen Sie unser Whitepaper über die Herausforderungen netzwerkbasierter Ansätze für die Container-Segmentierung und wie Sie diese mithilfe hostbasierter Segmentierung überwinden können.


