.png)
Anatomie des conteneurs 101 : Qu'est-ce qu'un cluster ?
Du point de vue de la mise en réseau, les conteneurs étendent le réseau "" - la limite entre les décisions d'acheminement du réseau et l'arrivée d'un paquet à sa destination finale - à l'intérieur d'un hôte. La périphérie n'est plus l'interface réseau d'un hôte, mais se situe à plusieurs niveaux dans les constructions logiques d'un hôte. La topologie du réseau est abstraite et s'étend profondément dans ces constructions logiques au sein d'un hôte, sous la forme de tunnels de réseau superposés, d'interfaces virtuelles, de frontières NAT, d'équilibreurs de charge et de plugins de mise en réseau. Les architectes de réseaux et de sécurité ne peuvent plus ignorer les aspects internes des systèmes d'exploitation lorsqu'ils conçoivent leurs architectures. Les conteneurs obligent ces architectures à comprendre où va un paquet après avoir traversé la carte d'interface réseau d'un hôte.
Systèmes d'orchestration
Cela dit, un système d'orchestration est nécessaire pour mettre de l'ordre dans les environnements de conteneurs. Un système d'orchestration gère les détails relatifs à l'organisation, à la mise à l'échelle et à l'automatisation des conteneurs, et crée des constructions logiques autour de divers composants pertinents pour le comportement des conteneurs. Ils sont également responsables de l'organisation des frontières logiques associées à l'exécution des conteneurs et de la création de constructions logiques auxquelles une adresse IP peut être attribuée. Cela dit, ces systèmes sont externes et ne peuvent pas réellement déployer et gérer le cycle de vie des instances d'exécution de conteneurs spécifiques, qui sont toujours gérées par Docker, par exemple.
Il existe de nombreux systèmes d'orchestration de conteneurs, mais les deux plus utilisés aujourd'hui sont Kubernetes et OpenShift. Ils atteignent tous deux les mêmes objectifs de base, la principale différence étant que l'un est un projet et l'autre un produit : Kubernetes est un projet né en grande partie de Google, et OpenShift est un produit appartenant à Red Hat. D'une manière générale, Kubernetes est le plus souvent utilisé dans des environnements de cloud public et OpenShift est le plus souvent utilisé dans des centres de données sur site, mais il existe un chevauchement important entre les deux. En bref, Kubernetes sous-tend les deux approches, avec quelques légères différences de terminologie entre chacune d'entre elles.
Une brève histoire des conteneurs
Croyez-le ou non, les conteneurs sont antérieurs à Kubernetes. Docker, par exemple, a lancé sa plateforme de conteneurs en 2013, tandis que Kubernetes n'a lancé son projet axé sur le cloud public qu'en 2014. OpenShift a été lancé avant les deux, en mettant l'accent sur les hôtes déployés dans des centres de données sur site.
Le simple fait de déployer des conteneurs d'exécution sur un hôte local répond généralement aux besoins des développeurs, car les conteneurs d'exécution peuvent communiquer entre eux via "localhost" et des ports uniques. Aucune adresse IP spécifique n'est attribuée aux exécutions de conteneurs. Si vous vous concentrez sur l'écriture d'un code rapide et efficace et sur le déploiement de votre application à travers une collection de conteneurs d'exécution associés, cette approche fonctionne bien. Mais si vous voulez que cette application accède à des ressources externes en dehors de l'hôte local, ou si vous voulez que des clients externes accèdent à cette application, vous ne pouvez pas ignorer les détails du réseau. C'est l'une des raisons pour lesquelles un système d'orchestration est nécessaire.
Kubernetes a été créé autour d'un ensemble de blocs de construction et d'un flux de travail piloté par API afin d'organiser le comportement des moteurs d'exécution des conteneurs. Dans cette approche, Kubernetes crée une série de constructions logiques à l'intérieur et entre les hôtes associés à un environnement conteneurisé spécifique, et crée un tout nouvel ensemble de vocabulaire pour se référer à ces constructions. Alors que Kubernetes applique ces blocs de construction et ces flux de travail pilotés par API autour d'un ensemble de mesures de calcul associées à l'allocation de CPU, aux besoins en mémoire et à d'autres mesures telles que le stockage, l'authentification et le comptage, la plupart des professionnels de la sécurité et de la mise en réseau se concentrent sur une seule chose :
Quelles sont les limites que franchit un paquet IP lorsqu'il est en route vers une construction logique à laquelle est attribuée une adresse IP ?
Du point de vue de la mise en réseau, Kubernetes et OpenShift créent tous deux des constructions logiques et pertinentes dans une approche hiérarchique, avec seulement une légère différence de vocabulaire entre chaque système. Cette situation est illustrée ci-dessous.
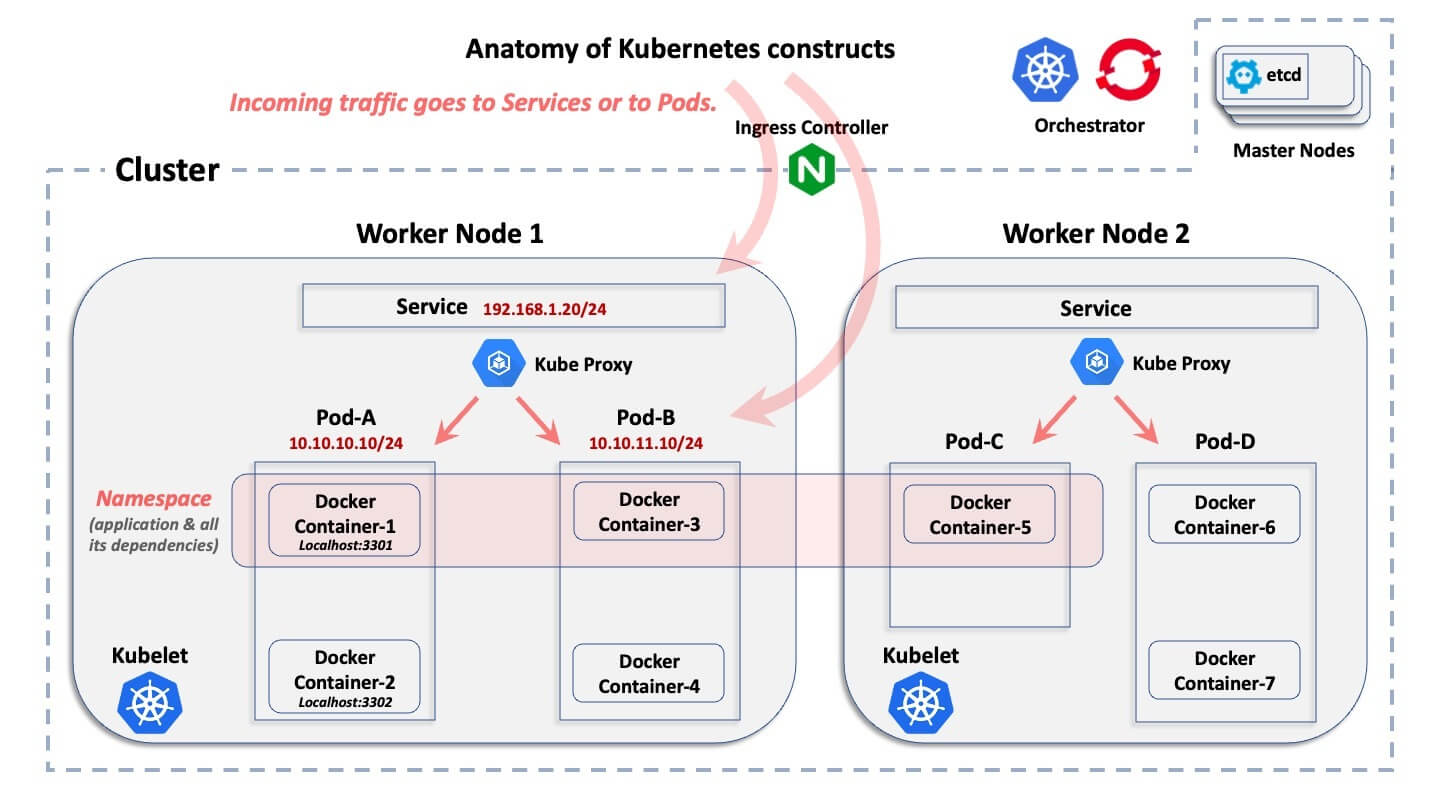
L'ABC des grappes de conteneurs
Ce diagramme montre la construction logique de base d'un environnement Kubernetes. Il n'explique pas ce que fait chaque construction, mais seulement comment elles sont logiquement liées les unes aux autres.
En partant de la construction la plus large jusqu'à la plus petite, voici quelques explications rapides :
- Cluster:Un cluster est l'ensemble des hôtes associés à un déploiement conteneurisé spécifique.
- Les nœuds:À l'intérieur d'une grappe, il y a des nœuds. Un nœud est l'hôte sur lequel résident les conteneurs. Un hôte peut être un ordinateur physique ou une machine virtuelle, et il peut résider dans un centre de données sur site ou dans un nuage public. En général, il existe deux catégories de nœuds dans une grappe : les "nœuds maîtres" et les "nœuds travailleurs". Pour simplifier à l'extrême, un nœud maître est le plan de contrôle qui fournit la base de données centrale du cluster et le serveur API. Les nœuds de travail sont les machines qui exécutent les pods d'application réels.
- Pods:À l'intérieur de chaque nœud, Kubernetes et OpenShift créent des pods. Chaque pod englobe un ou plusieurs conteneurs et est géré par le système d'orchestration. Les pods se voient attribuer des adresses IP par Kubernetes et OpenShift.
- Conteneur:C'est à l'intérieur des pods que résident les moteurs d'exécution des conteneurs. Les conteneurs d'un module donné partagent tous la même adresse IP que ce module et communiquent entre eux via Localhost, en utilisant des ports uniques.
- Espace de noms:Une application donnée est déployée "horizontalement" sur plusieurs nœuds d'un cluster et définit une frontière logique pour allouer des ressources et des autorisations. Les pods (et donc les conteneurs) et les services, mais aussi les rôles, les secrets et de nombreuses autres constructions logiques appartiennent à un espace de noms. OpenShift appelle cela un projet, mais il s'agit du même concept. En règle générale, un espace de noms correspond à une application spécifique, qui est déployée dans tous les conteneurs qui lui sont associés. Un espace de noms n'a rien à voir avec un réseau et une structure de sécurité (différent d'un espace de noms IP Linux).
- Service:Étant donné que les pods peuvent être éphémères (ils peuvent disparaître soudainement et être redéployés plus tard de manière dynamique), un service est un "front-end", qui est déployé devant un ensemble de pods associés et fonctionne comme un équilibreur de charge avec un VIP qui ne disparaît pas si un pod disparaît. Un service est une construction logique non éphémère, avec sa propre adresse IP. À quelques exceptions près dans Kubernetes et OpenShift, les connexions externes pointent vers l'adresse IP d'un service et sont ensuite transmises à des pods "backend".
- Serveur API Kubernetes: C'est ici que le flux de travail de l'API est centralisé, Kubernetes gérant la création et le cycle de vie de toutes ces constructions logiques.
Défis en matière de sécurité avec les conteneurs
Afin de créer des segments de sécurité le long des frontières des charges de travail, il est nécessaire de comprendre ces constructions logiques de base créées par Kubernetes. Le trafic réseau externe entrant et sortant de l'application hébergée ne pointe généralement pas vers l'adresse IP de l'hôte sous-jacent, le nœud. Au lieu de cela, le trafic réseau pointera vers un service ou un pod au sein de cet hôte. Par conséquent, les services et les modules associés à une charge de travail doivent être suffisamment bien compris pour créer une architecture de sécurité par segmentation efficace.
Vous souhaitez en savoir plus ? Consultez notre article sur les défis posés par les approches réseau de la segmentation des conteneurs et sur la façon de les surmonter en utilisant la segmentation basée sur l'hôte.


