.png)
Containers Anatomy 101: ¿Qué es un Cluster?
Desde una perspectiva de red, los contenedores extienden el "borde" de la red, el límite entre las decisiones de reenvío de red y un paquete que llega a su destino final, profundamente en un host. El borde ya no es la interfaz de red de un host, sino que tiene varias capas de profundidad en construcciones lógicas dentro de un host. Y la topología de red se abstrae y profundiza en estas construcciones lógicas dentro de un host, en forma de túnel de red superpuesto, interfaces virtuales, límites NAT, equilibradores de carga y complementos de red. Los arquitectos de redes y seguridad ya no pueden ignorar los aspectos internos del sistema operativo al diseñar sus arquitecturas. Los contenedores obligan a estas arquitecturas a comprender a dónde va un paquete luego de pasar por la NIC de un host.
Sistemas de orquestación
Dicho esto, se requiere un sistema de orquestación para traer algún tipo de orden a los entornos de contenedores. Un sistema de orquestación gestiona los detalles relacionados con la organización, el escalado y la automatización de contenedores, y crea construcciones lógicas en torno a varios componentes que son relevantes para el comportamiento de los contenedores. También son responsables de organizar los límites lógicos asociados con los tiempos de ejecución de contenedores y crear construcciones lógicas a las que se les pueda asignar una dirección IP. Dicho esto, estos sistemas son externos y no pueden implementar y gestionar el ciclo de vida de instancias de tiempo de ejecución de contenedores específicos, que aún son manejadas por Docker, por ejemplo.
Hay muchos sistemas de orquestación de contenedores, pero los dos más empleados hoy en día son Kubernetes y OpenShift. Ambos logran los mismos objetivos básicos, con la principal diferencia de que uno es un proyecto y el otro es un producto: Kubernetes es un proyecto nacido en gran parte de Google, y OpenShift es un producto propiedad de Red Hat. En términos generales, Kubernetes se ve con mayor frecuencia en entornos de nube pública y OpenShift se ve con mayor frecuencia en centros de datos locales, pero existe una cantidad significativa de superposición entre los dos. En resumen, Kubernetes subyace a ambos enfoques, con una ligera diferencia en la terminología entre cada uno.
Una breve historia de los contenedores
Lo creas o no, los contenedores son anteriores a Kubernetes. Docker, por ejemplo, lanzó por primera vez su plataforma de contenedores en 2013, mientras que Kubernetes no lanzó su proyecto centrado en la nube pública hasta 2014. OpenShift se lanzó antes que ambos, con un enfoque en hosts implementados en centros de datos locales.
La simple implementación de entornos de ejecución de contenedores en un host local generalmente satisface las necesidades de los desarrolladores, ya que los tiempos de ejecución pueden comunicar entre sí a través de "localhost" y puertos únicos. A los entornos de ejecución de contenedores no se les asignan direcciones IP específicas. Si se centra en escribir código rápido y eficaz e implementar la aplicación en una colección de entornos de ejecución de contenedores asociados, este enfoque funciona bien. Pero si desea que esa aplicación acceda a recursos externos fuera del host local, o si desea que los clientes externos accedan a esa aplicación, no puede ignorar los detalles de red. Esta es una de las razones por las que se necesita un sistema de orquestación.
Kubernetes se creó en torno a un conjunto de bloques de construcción y un flujo de trabajo basado en API para organizar el comportamiento de los tiempos de ejecución de los contenedores. En este enfoque, Kubernetes crea un serial de construcciones lógicas dentro y entre hosts asociados con un entorno en contenedores específico, y crea un conjunto completamente nuevo de vocabulario para hacer referencia a estas construcciones. Si bien Kubernetes aplica estos bloques de creación y flujos de trabajo basados en API en torno a un conjunto de métricas informáticas asociadas con la asignación de CPU, los requisitos de memoria y otras métricas como el almacenamiento, la autenticación y la medición, la mayoría de los profesionales de seguridad y redes se centran en una cosa:
¿Qué límites atraviesa un paquete IP cuando está en camino a alguna construcción lógica a la que se le asigna una dirección IP?
Desde una perspectiva de redes, tanto Kubernetes como OpenShift crean construcciones lógicas y relevantes en un enfoque jerárquico, con solo una ligera diferencia en el vocabulario entre cada sistema. Esto se ilustra a continuación.
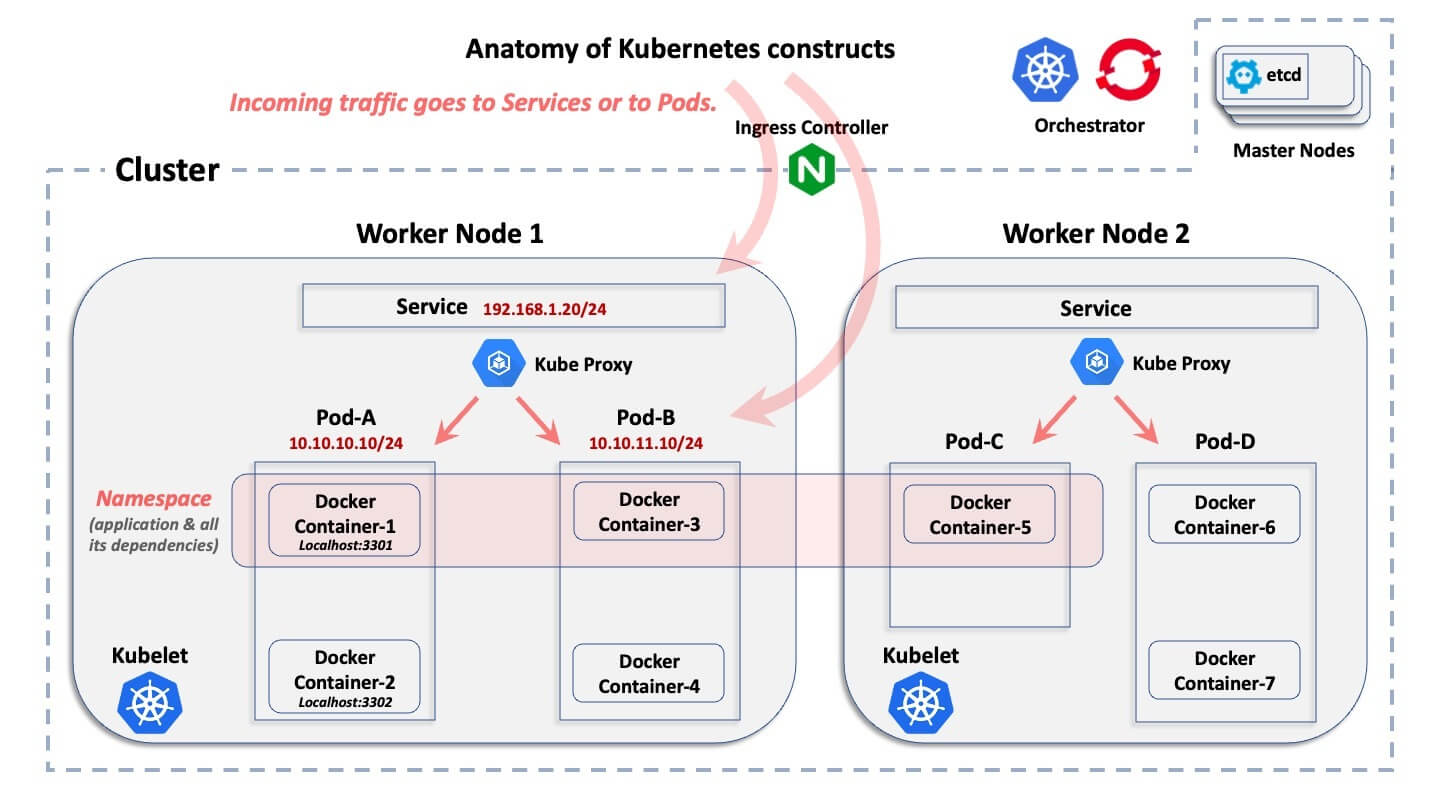
El ABC de un clúster de contenedores
Este diagrama muestra la construcción lógica básica de un entorno de Kubernetes. No explica lo que hace cada constructo, sino solo cómo se relacionan lógicamente entre sí.
Comenzando desde la construcción más amplia hasta la más pequeña, aquí hay explicaciones rápidas:
- Clúster: Un clúster es la colección de hosts asociados a una implementación específica en contenedores.
- Nodos: dentro de un clúster, hay nodos. Un nodo es el host en el que residen los contenedores. Un host puede ser un equipo físico o una máquina virtual, y puede residir en un centro de datos local o en una nube pública. Generalmente, hay dos categorías de nodos en un clúster: los "nodos maestros" y los "nodos de trabajo". Para simplificar demasiado las cosas, un nodo maestro es el plano de control que proporciona la base de datos central del clúster y el servidor de API. Los nodos de trabajo son las máquinas que ejecutan los pods de aplicaciones reales.
- Pods: dentro de cada nodo, tanto Kubernetes como OpenShift crean pods. Cada pod abarca uno o varios entornos de ejecución de contenedores y es gestionado por el sistema de orquestación. Kubernetes y OpenShift asignan direcciones IP a los pods.
- Contenedor: dentro de los pods es donde residen los tiempos de ejecución del contenedor. Todos los contenedores de un pod determinado comparten la misma dirección IP que ese pod y se comunican entre sí a través de Localhost, mediante puertos únicos.
- Espacio de nombres: una aplicación determinada se implementa "horizontalmente" en varios nodos de un clúster y define un límite lógico para asignar recursos y licencias. Los pods (y, por lo tanto, los contenedores) y los servicios, pero también los roles, los secretos y muchas otras construcciones lógicas pertenecen a un espacio de nombres. OpenShift llama a esto un proyecto, pero es el mismo concepto. En términos generales, un espacio de nombres se asigna a una aplicación específica, que se implementa en todos los contenedores asociados dentro de ella. Un espacio de nombres no tiene nada que ver con una construcción de red y seguridad (diferente de un espacio de nombres IP de Linux)
- Servicio: dado que los pods pueden ser efímeros (pueden desaparecer repentinamente y luego volver a implementar dinámicamente), un servicio es un "front-end", que se implementa frente a un conjunto de pods asociados y funciona como un equilibrador de carga con una VIP que no desaparece si desaparece un pod. Un servicio es una construcción lógica no efímera, con su propia dirección IP. Con solo unas pocas excepciones dentro de Kubernetes y OpenShift, las conexiones externas apuntan a la dirección IP de un servicio y luego se reenvían a pods de "backend".
- Servidor de API de Kubernetes: Aquí es donde se centraliza el flujo de trabajo de la API, con Kubernetes gestionando la creación y el ciclo de vida de todas estas construcciones lógicas.
Desafíos de seguridad con contenedores
Para crear segmentos de seguridad a lo largo de los límites de la carga de trabajo, es necesario comprender estas construcciones lógicas básicas creadas por Kubernetes. El tráfico de red externa que entra y sale de la aplicación hospedada generalmente no apuntará a la dirección IP del host subyacente, el nodo. En su lugar, el tráfico de red apuntará a un servicio o a un pod dentro de ese host. Por lo tanto, los servicios y pods asociados a una carga de trabajo deben comprender lo suficiente para crear una arquitectura de seguridad de segmentación eficaz.
¿Interesado en más? Consulte nuestro documento sobre los desafíos de los enfoques basados en la red para la segmentación de contenedores y cómo superarlos mediante la segmentación basada en host.


